
《关于golang哈希表触发扩容条件是装载因子为6.5或溢出桶数量过多这件事》
在阅读了Go 语言设计与实现的3.3 哈希表实现原理之后,了解到哈希表的扩容有两个触发条件:
- 装载因子达到 6.5
- 溢出桶过多
我想到了两个问题:
- 装载因子为什么是 6.5,不能选择其他数字么?
- 溢出桶过多,判断标准是什么,怎样才算过多?
带着疑问查询相关资料,并作了总结,代码使用gov1.18。
1. 触发扩容的装载因子值为什么是 6.5
runtime/map.go的注释中有说明不同的装载因子对于哈希表的性能影响:
// Picking loadFactor: too large and we have lots of overflow
// buckets, too small and we waste a lot of space. I wrote
// a simple program to check some stats for different loads:
// (64-bit, 8 byte keys and elems)
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
//
// %overflow = percentage of buckets which have an overflow bucket
// bytes/entry = overhead bytes used per key/elem pair
// hitprobe = # of entries to check when looking up a present key
// missprobe = # of entries to check when looking up an absent key
//
// Keep in mind this data is for maximally loaded tables, i.e. just
// before the table grows. Typical tables will be somewhat less loaded.
装载因子和溢出桶比率的关系
对于溢出桶的比例%overflow,由上可以看出,在装载因子在6.5之后,溢出桶的比例扩大速度会增加(相较于6.5之前)。将数据进行简单的多项式拟合可以的出以下图表:
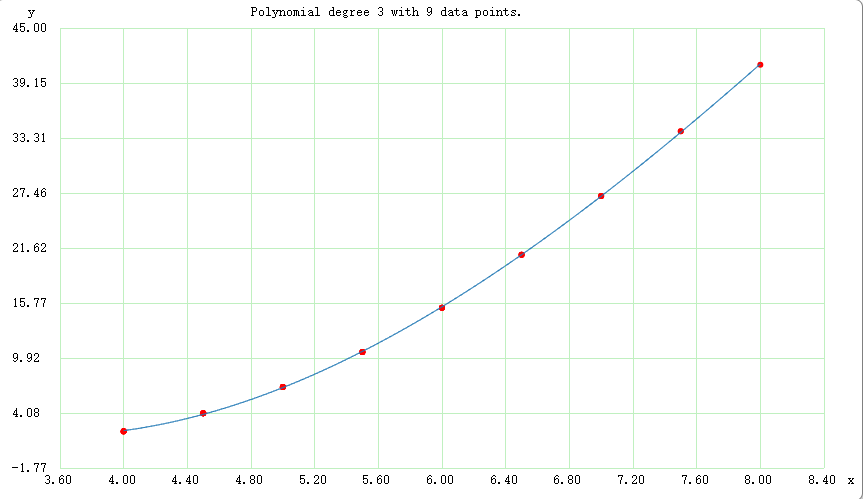
由上图可以看出,装载因子在6.5之后,溢出桶的变化速率明显加快。
装载因子和键值对占用字节数的关系
若将装载因子loadFactor和bytes/entry进行简单的拟合:
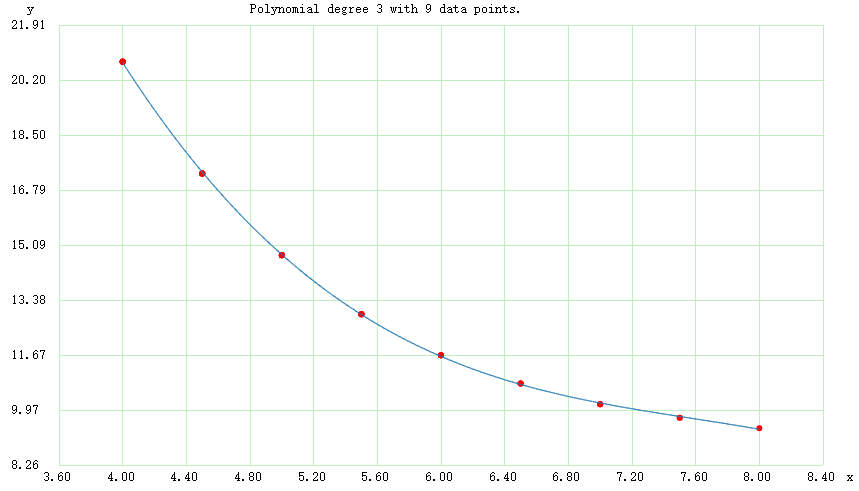
由上图可以看出当装载因子超过6.5时,键值对所占用的内存大小的增大比率明显放缓;若选取较小的装载因子进行扩容,会导致较多的空闲容量无法利用。
装载因子与hitprobe和missprobe的关系
随着装载因子的增长,hitprobe和missprobe均为线性的,不会出现明显的波动。
小结
触发扩容的装载因子值为6.5,是根据实验数据,平衡空间利用率和溢出桶数量的结果
2. 触发扩容的溢出桶数量是多少
溢出桶数量是否过多由函数runtime.tooManyOverflowBuckets判断:
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
由注释中的
"too many" means (approximately) as many overflow buckets as regular buckets.
可以得出:“太多”的意思是溢出桶的数量(近似)和正常桶的数量一样多
此处有个值得关注的点,就是以正常桶的数量为 为界,有不同的处理:
- 当正常桶的数量小于等于 时,直接比较溢出桶的数量(此时是准确值)和正常桶数量,大于等于则判定溢出桶过多
- 当正常桶的数量大于 时,将比较溢出桶的数量(此时是近似值)和 ,大于等于则判定溢出桶过多
上述条件中出现了近似值,是因为溢出桶的数量计算也有两种不同的情况,根据函数runtime.incroverflow:
// incrnoverflow increments h.noverflow.
// noverflow counts the number of overflow buckets.
// This is used to trigger same-size map growth.
// See also tooManyOverflowBuckets.
// To keep hmap small, noverflow is a uint16.
// When there are few buckets, noverflow is an exact count.
// When there are many buckets, noverflow is an approximate count.
func (h *hmap) incrnoverflow() {
// We trigger same-size map growth if there are
// as many overflow buckets as buckets.
// We need to be able to count to 1<<h.B.
if h.B < 16 {
h.noverflow++
return
}
// Increment with probability 1/(1<<(h.B-15)).
// When we reach 1<<15 - 1, we will have approximately
// as many overflow buckets as buckets.
mask := uint32(1)<<(h.B-15) - 1
// Example: if h.B == 18, then mask == 7,
// and fastrand & 7 == 0 with probability 1/8.
if fastrand()&mask == 0 {
h.noverflow++
}
}
可以看出:
- 当桶的数量小于 时,溢出桶的数量将直接增加,此时溢出桶的数量是准确值
- 当桶的数量大于 时,溢出桶的数量只有的概率增加,此时溢出桶的数量是近似值
其中的fastrand是采用Xorshift RNGs生成的伪随机数。
也就是说当桶的数量大于 时,此时溢出桶的数量增加概率只有,若此时溢出桶的数量(近似值)大于等于,说明其准确值可能超出这个数很多,可以近似的认为和正常桶的数量相同了。
小结
当溢出桶的数量和正常桶的数量(近似)相同时,会被认为有着过多的溢出桶